Chatbot’s intelligence – language models

Chatbots are commonly known as artificial intelligence. They recognize and interpret the content provided by the user and adjust the appropriate response to it. The intelligence of chatbots is based on nothing more than a natural language processing system. In order to create a well-functioning solution, it is crucial to select an appropriate language model that meets the challenges it faces.
There are three categories of natural language processing algorithms – linguistic model, machine learning (ML) and large language models (LLM). The choice of model should be suited to both the content and the way it is presented in the chatbot, as well as the audience that will use it.
Linguistic model
The linguistic approach in speech recognition involves matching keywords, also known as training phrases. This means that the user’s message is searched for phrases that have been previously entered into the intent of the bot. The matching in the case of the linguistic model must be almost complete. Of course, there are a few ways to develop this type of concept, including using a feature that corrects typos or integrating with an external linguistic database that generates variations of a word or phrase.
The linguistic model implemented in the KODA platform can use several modes. It gives a wider range of possibilities for usage:
- By selecting a mode in which the user’s message must contain at least one phrase, it searches for words and matches the highest-priority intention fulfilling this condition.
- Using linguistic corpus, we base on the initial phrase in a word by matching any form of the word, such as plural or variety.
- Even mode requires a complete match of the phrase from the intent with the user’s message.
- Also, under this type of linguistic approach, it is possible to rely on entities – sets of words – which can be treated as lists of synonyms or similar words, and a minimum of one of each must appear in the user’s message.
Training such a language model involves verifying training phrases from intentions with user messages. Teaching the bot in this case is mostly about adding phrases or new ways a user can ask for something, for example, when to expect the biggest queues. The language – not only Polish – can be very varied and even when we come up with 50 terms for something, a user may use 51 or type a word with such a spelling mistake that no one would think of. That’s why it’s important (and, we must admit, sometimes very interesting) to review conversations regularly.
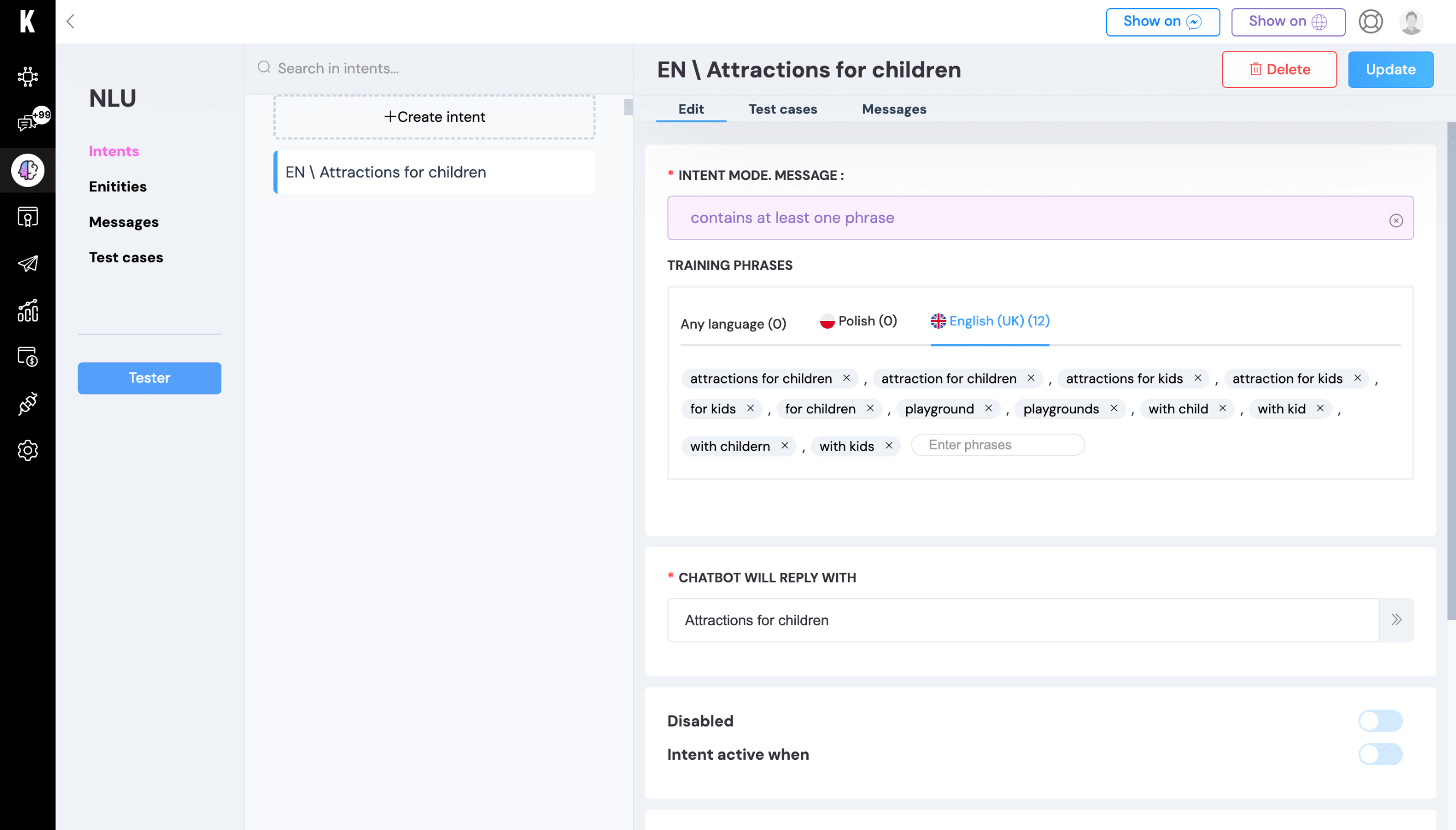
The linguistic model works well for less varied intentions, where the precision of the response is more important. Using such a natural language recognition method gives us more control over the detectability of even very precise intentions right from the beginning. The linguistic approach has the limitation of not being able to match similar phrases based on probability.
Machine learning (ML)
The second method of natural language recognition in bots is to use Machine Learning – advanced statistical systems that collect data, process it, and then learn from it.
The main differences between the linguistic approach and machine learning are probability and types of training phrases. With the machine learning method, the bot creator decides what level of probability is required for a solution. The lower the level, the more the user’s messages may differ from those given during bot’s production. ML provides the opportunity to input examples in the form of longer, often more complex sentences. In addition, in example phrases or training sentences, there is an opportunity to mark entities – a place where the bot has the ability to substitute a synonym or equivalent during intent detection. These can be locations, proper names, dates, or collections we define.
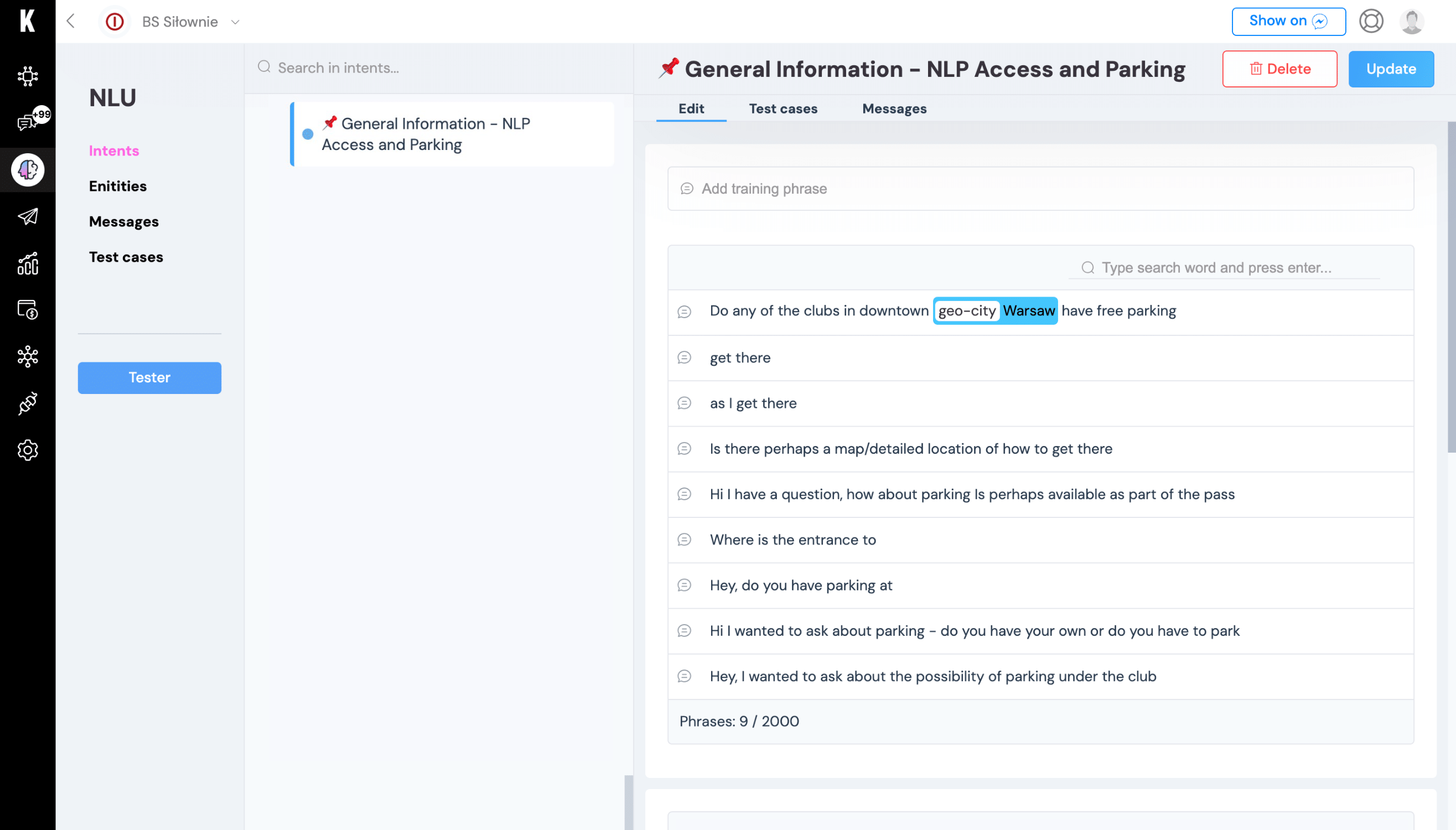
Although it’s hard to believe, training an ML-based bot is even simpler than one with a linguistic model. All you need to do is to assign the message typed by the user to the appropriate intention. And that’s it – it will appear as another training phrase and the machine will have additional information to process and teach our bot. How often should we do this? The more often, the better! Any of you – reading this now – could ask a question, for example, about the opening hours of a store in a different way. The more such samples ML receives, the more of us the bot will understand, and after all, that’s what it’s all about at the end of the day.
A language model based on machine learning provides greater opportunities for interpreting user-submitted content and tagging certain information in it with entities. Moreover, regular training of bots operating on this model makes the accuracy of detected messages increase significantly. The ML model will work well in solutions that have a large base of initial training phrases and trained conversations. Did this model work for us in all implementations? Not necessarily – for example, we didn’t want the bot to mistakenly point out to us the hours of feeding the animals if we were looking for a restaurant.
Large language model (LLM)
Recently, large language models (LLM) have become increasingly popular, and among the most well-known is ChatGPT. With this approach, the answer to a question asked by the user is searched based on a prompt (the instructions the artificial intelligence should follow in generating the answer) in the knowledge database.
This method, with relatively small input, gives very large possibilities during the response generation. Crucial to LLM is the prompt creation. A well-constructed prompt will produce a satisfactory answer. The temperature of the received answer is also not insignificant – it is an indicator of the level of the diversity of the outcome. The higher it is, the more creative, and therefore possibly less precise and relevant to the topic, are the messages generated by AI.

The undoubted advantage of models like ChatGPT is the very wide range of knowledge they build from publicly available online data. They also allow more efficient searching among data, comparing or contrasting them with each other. However, it is important to pay attention to the sources from which the generated answers are pulled, to make sure that the information provided by the bot is reliable. So it is worth (already at the level of prompt design) to think about the risks that may affect the performance of our solution. Let’s think early on what limitations we should put on ChatGPT, because we know that it can be creative – not necessarily to the benefit of the brand we are promoting.
Which model to choose?
It is not possible to say which of the language models used in bot production is the best, most effective, most intelligent. In selecting a model, it is necessary to take into consideration the scope of bot’s knowledge, the type of questions, the audience and the way they communicate with the virtual assistant. Thanks to our experience with different methods and knowledge of their limitations and capabilities, we can design solutions with much greater knowledge and effectiveness. And what if the method we choose doesn’t work? Let’s change it – let’s use a different one – let’s experiment and adjust them according to our needs. If some of the questions fit more with the linguistic approach and others with the machine learning, then let’s combine them. How intelligent our bots will be depending on how creative we are during their production.
Contact with us
You are one step away from separating yourself from the communication community in your organization
You can contact us and we will prepare a dedicated offer for you.